
mencoba platrofm n8n yang sedang marak digunakan
Sebagai backend developer, membangun chatbot AI di tahun 2026 sering terlihat mudah berkat banyaknya tools no-code dan low-code. Namun, dengan memanfaatkan n8n, proses produksi bisa menjadi jauh lebih sederhana tanpa mengorbankan kualitas dan fleksibilitas.
Artikel ini merangkum perjalanan saya membangun chatbot berbasis Gemini, n8n, dan Supabase (PostgreSQL + pgvector). Use case yang saya gunakan cukup sederhana: file PDF berupa resume (CV) yang diambil dari Google Drive, kemudian dijadikan sebagai knowledge base oleh chatbot.
nantinya pertanyaan yg berkaitan dengan profil di Resume saya bisa dijawab oleh AI, contohnya "Apakah Damar bisa menggunakan PHP?", "Berapa tahun exp Damar di Backend?"
ini jg bisa menggunakan PDF apapun, jadi pada dasarnya sistem akan dpt data pdf dan bisa jawab apapun terkait pdf tsb
1. Kenapa Harus Vector? Apa Itu Vector Database?
Pertanyaan umum:
Kenapa tidak menggunakan query seperti LIKE %keyword% saja?
Jawabannya sederhana:
Komputer tidak memahami kata, tetapi memahami angka.
Di sinilah vector embeddings berperan. Teks akan dikonversi menjadi representasi numerik berupa koordinat dalam ruang multidimensi.
Contoh sederhana:
"Damar" dikonversi menjadi [-0.0138, 0.0128, ...]Perbedaan Keyword Search vs Vector Search
Keyword Search
Jika user bertanya:
"Apa keahlian si Damar?"
Namun di resume tertulis:
"Memiliki kompetensi teknis..."
Maka pencarian berbasis keyword akan gagal.
Vector Search
Dengan embedding model (Gemini), AI memahami bahwa "keahlian" dan "kompetensi" memiliki makna yang mirip (berada di koordinat yang berdekatan).
Hasilnya, chatbot tetap bisa memberikan jawaban yang relevan.
Tanpa vector, chatbot hanyalah mesin pencari kata, dengan vector, chatbot mulai “memahami” makna.
Konfigurasi yang Saya Gunakan
- Model:
gemini-embedding-001 - Vector size:
3072
Trade-off:
- Semakin besar dimensi → kualitas pemahaman meningkat
- Namun → storage lebih besar & query lebih lambat
⚠️ Penting: Gunakan index pada kolom vector untuk performa optimal.
Contoh Implementasi di Supabase (pgvector)
-- Aktifkan extension vector
create extension if not exists vector;
CREATE TABLE chat_history (
id SERIAL PRIMARY KEY,
session_id TEXT NOT NULL,
message JSONB NOT NULL
);
CREATE TABLE documents (
id uuid PRIMARY KEY DEFAULT gen_random_uuid(),
content text,
metadata jsonb,
embedding vector(3072)
);
-- Fungsi similarity search
create or replace function match_documents (
query_embedding vector(768),
match_count int DEFAULT 5,
filter jsonb DEFAULT '{}'
) returns table (
id uuid,
content text,
metadata jsonb,
similarity float
)
language plpgsql
as $$
begin
return query
select
documents.id,
documents.content,
documents.metadata,
1 - (documents.embedding <=> query_embedding) as similarity
from documents
where documents.metadata @> filter
order by documents.embedding <=> query_embedding
limit match_count;
end;
$$;💡 Catatan:
Node Supabase Vector Store di n8n akan memanggil fungsi seperti match_documents. Karena belum tersedia secara default, fungsi ini perlu dibuat manual.
2. Arsitektur Dua Jalur: Ingestion & Chatbot
Untuk membangun sistem RAG (Retrieval-Augmented Generation) yang rapi, saya membagi workflow menjadi dua jalur utama:
Flow A: Knowledge Ingestion (Offline)
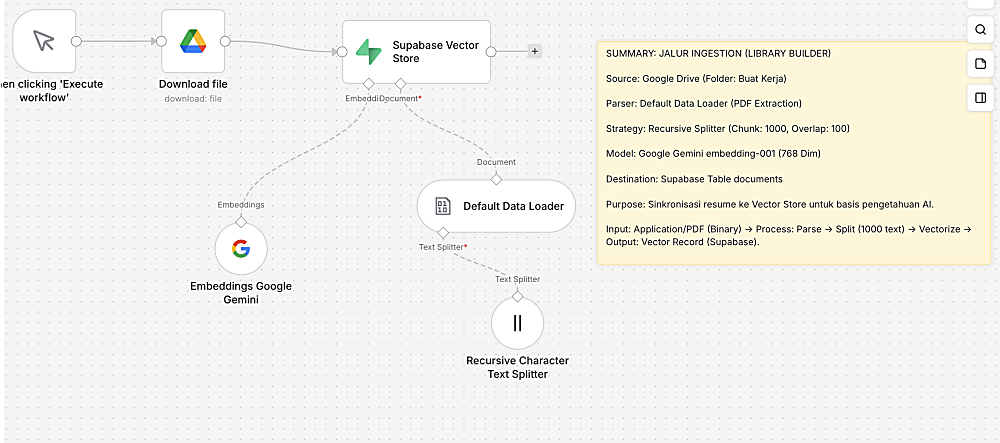
*klik untuk memperbesar
Proses ini berfungsi untuk “mengisi otak” AI:
Source
Mengambil file resume dari Google DriveSplitting dan pdf Parsing
dokumen pdf tersebut akan masuk sebagai binary, data loader akan parsing itu ke text dan Memecah dokumen menjadi chunks agar tidak melebihi limit token dan tetap menjaga kualitas konteksVectorizing
Mengubah setiap potongan teks menjadi vector menggunakan GeminiStorage
Menyimpan teks + embedding ke Supabase (pgvector)
Flow B: Chatbot Interface (Realtime)
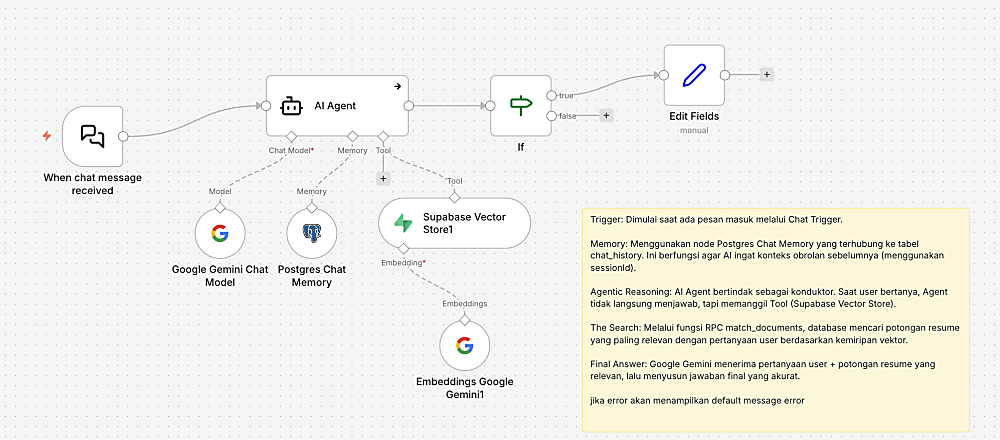
*klik untuk memperbesar
Ini adalah alur saat user berinteraksi:
Trigger
Menerima input dari userRetrieval
Mengubah pertanyaan menjadi vector, lalu mencari dokumen paling relevanAugmentation
Hasil dari Retrieval akan dijadikan context, lalu context tsb digabung dengan input chat , dan itu menjadi prompt ke llm GeminiGeneration
Gemini menggabungkan Pertanyaan user, Data relevan dari database (context) , menghasilkan jawaban finalMemory
Menggunakan Postgres Chat Memory (chat_history), Agar AI mengingat konteks percakapan berdasarkansession_id, setiap chat yg masuk akan ter record disini
3. Iterasi Berikutnya: Session-Based PDF Chat
Sistem ini masih akan terus dikembangkan. Fokus berikutnya adalah meningkatkan fleksibilitas dengan pendekatan session-based:
Dynamic Upload
User dapat mengunggah PDF langsung melalui chatSession Isolation
Setiap sesi memiliki konteks dokumen sendir, tidak tercampur dengan user lainStateless Privacy
Ketika sesi berakhir:- Context dihapus
- Memory dibersihkan
- Menjaga privasi & performa
4. Next Use Cases dengan n8n + Vector Database
Setelah berhasil membangun chatbot berbasis RAG, pendekatan ini sebenarnya bisa diperluas ke banyak use case lain. Dengan kombinasi n8n (workflow automation) + vector database (pgvector), kita bisa membangun sistem yang jauh lebih powerful dari sekadar chatbot.
Berikut beberapa ide pengembangan selanjutnya:
1. Reverse Image Search (Semantic Image Search)
Bukan hanya teks, gambar juga bisa diubah menjadi vector menggunakan model seperti CLIP atau embedding model dari Gemini.
Flow:
- User upload gambar
- n8n kirim ke model embedding (image → vector)
- Simpan vector di database
- Saat user cari gambar:
- convert gambar query → vector
- cari kemiripan di database
Use Case:
- Cari produk serupa (e-commerce)
- Duplicate image detection
- Visual search (mirip Google Images)
2. Multi-Document Chat (Beyond Resume)
Upgrade dari CV chatbot menjadi:
- Chat dengan banyak dokumen sekaligus
- Bisa lintas file (PDF, DOCX, TXT)
Contoh:
“Bandingkan kontrak A dan B”
n8n Role:
- Handle ingestion multi file
- Tag metadata (file_name, owner, category)
- Routing query ke dokumen relevan
3. Personal Knowledge Base (Second Brain AI)
Semua data personal bisa dijadikan knowledge:
- Notes
- Notion
- Slack
Flow:
- Sync data via n8n
- Convert ke vector
- Query via chatbot
Hasilnya: AI jadi seperti “otak kedua” yang bisa ditanya apa saja tentang data kita.
4. Recommendation System (Semantic Recommendation)
Tidak hanya “orang yang beli ini juga beli itu”, tapi:
- Berdasarkan makna dan preferensi user
Contoh:
“Saya suka backend dan distributed system”
AI bisa recommend:
- Artikel
- Course
- Produk
Karena menggunakan vector similarity, bukan rule-based.
5. Smart Document Classification & Routing
Gunakan vector untuk memahami isi dokumen secara otomatis.
Flow:
- Upload dokumen
- Embedding → vector
- Compare dengan kategori vector
Use Case:
- Auto classify invoice, contract, resume
- Routing ke service berbeda di n8n
6. Semantic Search API (Drop-in Search Engine)
Bangun API search yang jauh lebih pintar dari keyword search.
Contoh:
- Search produk
- Search artikel
- Search knowledge internal
Keunggulan:
- Tidak sensitif terhadap typo
- Mengerti sinonim
- Lebih relevan secara konteks
7. AI Assistant untuk Internal Tools
Integrasi ke sistem internal:
- CRM
- CMS
- Dashboard analytics
Contoh:
“Berapa total transaksi bulan lalu?”
AI bisa: Ambil data, Interpretasi dan Jawab dalam bahasa natural
Penutup
Membangun chatbot bukan sekadar menghubungkan API.
Sebagai engineer, tantangan utamanya adalah:
- Mengelola aliran data
- Menjaga performa
- Menjamin keamanan & privasi
- Membuat sistem tetap scalable
Dengan pendekatan yang tepat seperti RAG + vector database, chatbot bisa naik level dari sekadar keyword matcher menjadi sistem yang benar-benar memahami konteks.